Это материал из рубрики Failography - о моих фейлах. Можно почитать и набить себе шишки виртуально.
Летом 2015 после ухода с постоянного места работы я задался вопросом выбора проектов которыми хотел бы заниматься в свободном плавании. Одним из проектов был рейтинг Instagram аккаунтов, тегов / мест и фотографий. Про то что вышло с реализацией идеи я и опишу в данном блог постеПочему я выбрал данную идею?
Во первых это было интересно. Мне - всегда нравилось собирать данные, и как то их анализировать. Данных которые я планировал обрабатывать в инстаграме было - ну очень… очень много. Big data - мы идем к тебе =) Во вторых я не нашел нормальных конкурентов и реализованных сервисов. Даже сейчас есть сервисы показывающие рейтинг по фоловерам не более https://socialblade.com/instagram/top/100/followers У меня же формула включала не только фоловеров а и количество фото и лайков (их лайкИндекс если быть точным) - что могло давало совсем другие результаты топа. В топ попадали действительно красивые аккаунты с фотографиями - а не только звезды шоу бизнеса и кино.Монетизация
- Ставка номер 1 AdSense
- Продажа API к рейтингам для разработчиков разных приложений рекомендации тегов/рейтинг
- Платные сервисы юзерам (рекомендация самых популярных тегов по заданным выбранным итд)
Ингредиенты для разработки
Домен для проекта был выбран - instat.io Instagram очень ревниво относится к упоминанию себя в именах сервисах которые используют его api - даже к частице insta.. Просто назвать сервис InstagramStatistics можно - но не долго.. Технологически сервис создавался на php ( laravel 5 framework) / MySQL (Percona) & ElasticsearchВ базе сервиса были созданы такие таблицы brands filters photos place2photo places places_statistics tag2photo tags tags_statistics tasks_tags topics users users_statisticsПо названиям думаю все довольно понятно Таблички вида **_statistics используются для сгенерированных / сгруппированных рейтингов
Собираем данные - парсим инстаграм
Все в инстаграме крутится вокруг… сюрприз - фотографий (точнее медиа объектов фото и видео)! У фотографии есть теги, гео локация, автор а также данные о используемых фильтрах. Перебирая фотографии инстрагама - вы и узнаете о тегах, местах и пользователях сервиса. Получать данные о фотографиях мы будем с официального instagram api Я не стал использовал специальные бандлы/библиотеки для работы с instagram. А отправлял запросы по старинке curl-ом сразу к API Но чтобы начать сбор данных, нам нужны отправные точки. Я решил взять базу городов с населением более 100000 с geonames и начать обходить поиском по координатам инстаграм. Так база с каждым часом начала наполняться данными Единственное что не давало ускорить процесс рейт лимиты https://www.instagram.com/developer/limits/ При запуске они были сносными (около 5000 запросов в час) - сейчас они не гуманные полностью. 500 запросов в час для такого типа сервиса - капля в мореЗавариваем фронтенд с пакетика
Основная ставка в продвижении проекта была на бесплатный поисковый трафик (привлечения платного трафика в такой сервис - наверное не имеет смысла ) Попасть в выдачу по ВЧ запросам вида beautiful places instagram, tags for instagram, instagram tags, popular tags for likes, instagram hashtags, best instagram profiles - молодой сайт без существенного бюджета - не может Про instagram followers, view instagram photos, instagram pictures - лучшее вообще не думать Стратегия одна - пытаться попасть в топ по низкочастотным запросам вида Intstagram photos %cityname% / %tags% / instagram girls %city% итд Соответственно нам нужно вывести данный контент на сайте В качестве дизайна для сервиса берем растворимый пакетик тему за $15 с wrapbootrrap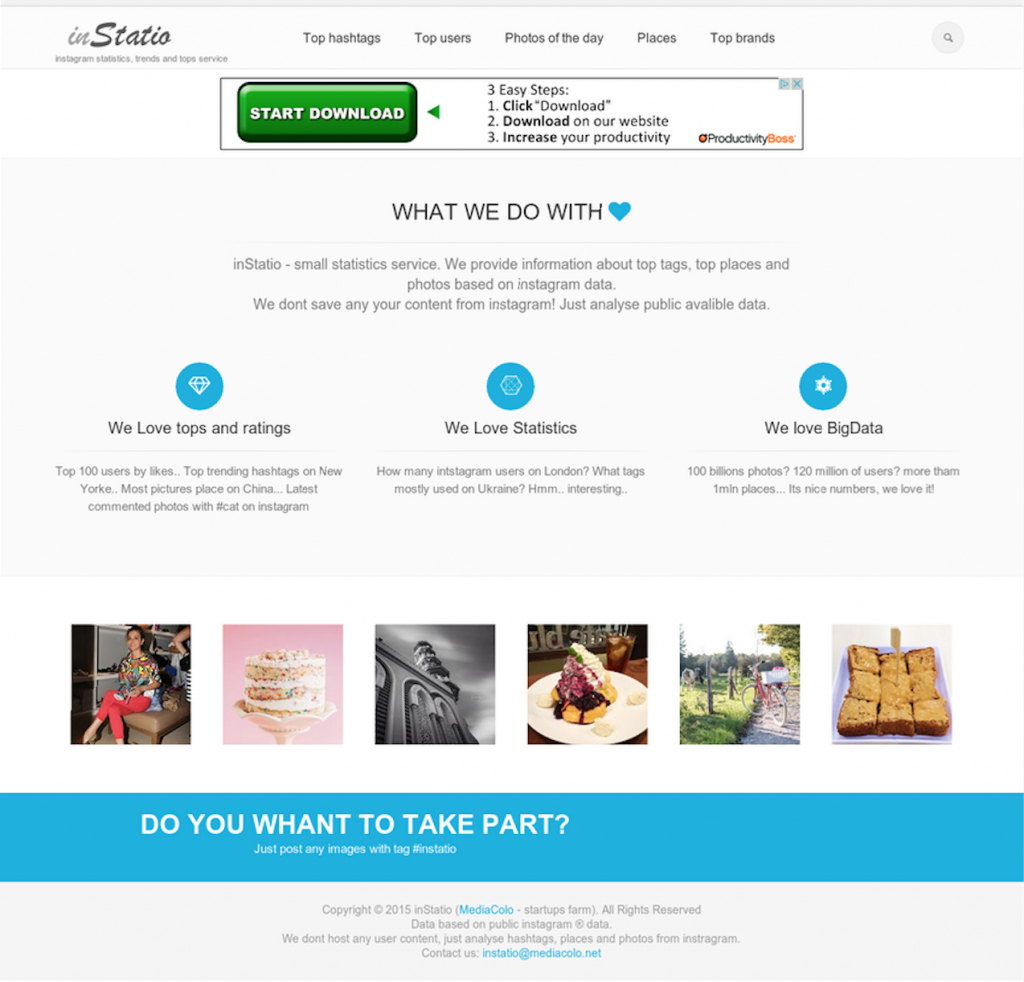 Да можно было потратить от 100уе до 5000 уе за супер уникальный дизайн с UI/UX проектированием и тестами, да и верстку сделать кастомную и хенд крафтед
Но столько инвестировать я не был готов ( правильно или нет - вопрос открыт )
Главное хранилище у проекта было MySQL но на веб сайте места / теги / фото и аккаунты выводились с elastic-а
Плюсы еластика - риалтайм индекс, без необходимости переиндексации.
Все очень быстро работает с разного рода группировками/сортировками поисками итд. Кластеризация с коробки (если нужно будет базу размазывать по нодам)
И самое главное - очень хотелось попробовать использовать его в бою (на прежних проектах с схожими задачами был sphinx )
Но есть у еластика одно но - ему нужна память… много памяти!
В итоге по мере роста количества данных, росло и поребление памяти
И требовалось использовать ноду 4-мя, потом 8.. 16.. Гб ОЗУ
Оперативная память не настолько дешевая на серверах - как диски, и надо было что-то решать
В итоге пришлось все перевести на кеш таблички и sphinx (пожертвовав риал таймом)
Да можно было потратить от 100уе до 5000 уе за супер уникальный дизайн с UI/UX проектированием и тестами, да и верстку сделать кастомную и хенд крафтед
Но столько инвестировать я не был готов ( правильно или нет - вопрос открыт )
Главное хранилище у проекта было MySQL но на веб сайте места / теги / фото и аккаунты выводились с elastic-а
Плюсы еластика - риалтайм индекс, без необходимости переиндексации.
Все очень быстро работает с разного рода группировками/сортировками поисками итд. Кластеризация с коробки (если нужно будет базу размазывать по нодам)
И самое главное - очень хотелось попробовать использовать его в бою (на прежних проектах с схожими задачами был sphinx )
Но есть у еластика одно но - ему нужна память… много памяти!
В итоге по мере роста количества данных, росло и поребление памяти
И требовалось использовать ноду 4-мя, потом 8.. 16.. Гб ОЗУ
Оперативная память не настолько дешевая на серверах - как диски, и надо было что-то решать
В итоге пришлось все перевести на кеш таблички и sphinx (пожертвовав риал таймом)
Запускаем
Сайт запустился в октябре 2015 года И спустя пару месяцев вышел на показатели 300-400 человек в сутки, что не так и много - я ожидал получить 10-ть раз больше пользователей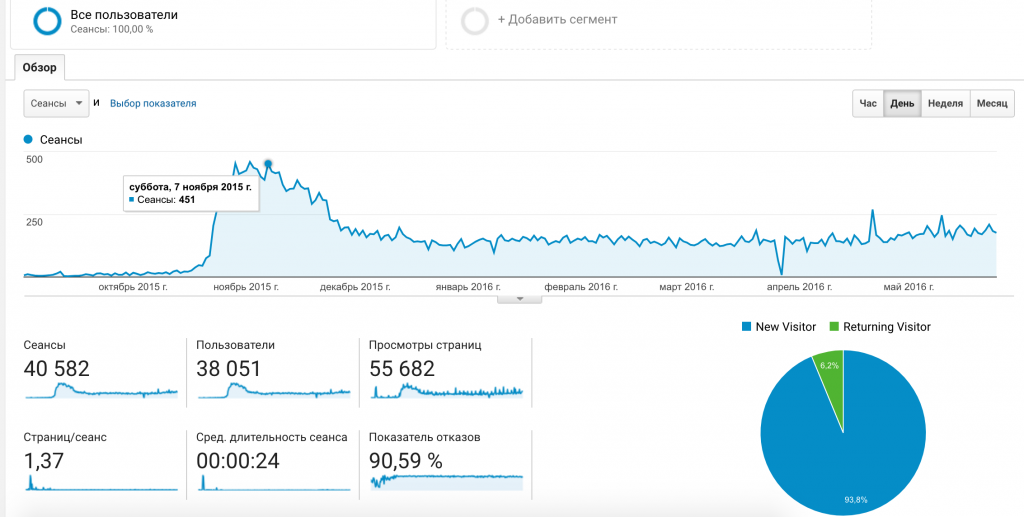
Закат
На всякие странички китайско/корейско/арабских тегов полились абузы от адсенса за адалтовость контента (видимо сам инстаграм не успевает все варианты ххххх добавлять в стоп слова и блокировать Но роботы гугл-а знают о нем лучшее…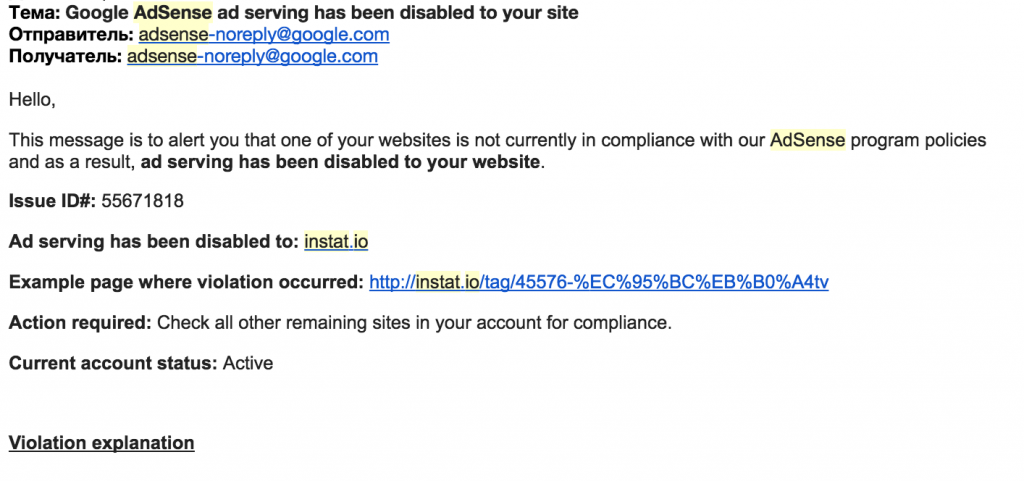 В итоге в один прекрасный день - весь сайт был забанил google adsense по домену (сейчас гугл обещает не банить сайты целиком а вводить пейдж левел санкции)
Желание развивать сайт дальше упало (ведь параллельно росли другие проекты)
Да и поисковый трафик тоже начал падать
Спустя пару месяцев я отключил индексацию
Чуть позже решил не продлевать даже домен
Частично собраная база тегов отображается на http://tagshashtags.com/
Проект собрал базу более 70Гб данных с инстаграма с милионами записями о фотографиях / тегах итд.. но не пошло
Проект закрыт - шишки набиты
Всем спасибо за внимание
В итоге в один прекрасный день - весь сайт был забанил google adsense по домену (сейчас гугл обещает не банить сайты целиком а вводить пейдж левел санкции)
Желание развивать сайт дальше упало (ведь параллельно росли другие проекты)
Да и поисковый трафик тоже начал падать
Спустя пару месяцев я отключил индексацию
Чуть позже решил не продлевать даже домен
Частично собраная база тегов отображается на http://tagshashtags.com/
Проект собрал базу более 70Гб данных с инстаграма с милионами записями о фотографиях / тегах итд.. но не пошло
Проект закрыт - шишки набиты
Всем спасибо за внимание